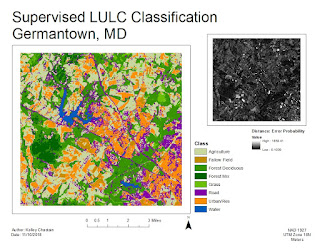
This week we continued to look at automated classifications, focusing on Supervised Classifications. Supervised Classification requires the user to set "training sets" to guide in the separation of the pixels into classes. The objective of the training sets is to select a homogeneous area for each spectral class. Selection of multiple training sets helps to identify the many possible spectral classes in each information class of interest. Training sets can be selected by 1)digitize polygons, that have a high degree of user control but often result in overestimate of spectral class and 2)seed pixel where the user sets thresholds. Both of these methods were utilized this week in lab. Training aids help evaluate spectral class separability, for example graphical plots like histograms, coincident spectral mean plots, or scatter plots. There are also statistical measures of separability like divergence or Mahalanobis distance. Parametric distance approaches are based on statistical parameters assuming normal distribution of the clusters (mean, std deviation, co-variance). Examples of parametric methods are mahalanobis distance, minimum distance and maximum likelihood. Non-Parametric distance approaches are not based on statistics but on discrete objects and simple spectral distance (examples are feature space and parallel-piped).
In lab this week we produced classified images from satellite data. We created spectral signatures and areas of interest (AOI) features utilizing both digitize polygons and seed pixels. We evaluated signatures by with histogram plots and mean plots to recognize and limit spectral confusion between spectral signatures. We classified images utilizing maximum likelihood classification and then merged classes and calculated area.

No comments:
Post a Comment